
Bron: artikel integraal overgenomen van devops.com
Origineel auteur: Partha Kanuparthy
Any computer system is only as useful as the accuracy and usefulness of the data it generates, whether it’s a modest departmental application or a predictive modeler used by an enormous cloud service provider. When a hyperscaler (which has a large network of data centers and a wide range of services) develops AI models, they simply have to produce robust predictions, or the effort is all for naught.
Any computer system is only as useful as the accuracy and usefulness of the data it generates, whether it’s a modest departmental application or a predictive modeler used by an enormous cloud service provider. When a hyperscaler (which has a large network of data centers and a wide range of services) develops AI models, they simply have to produce robust predictions, or the effort is all for naught.
Many variables can affect the accuracy of machine learning (ML) predictions, from the distribution of training data to the model’s (hyper)parameters to systems configuration. That makes identifying an issue’s root cause a complex problem, especially at Meta’s scale. Our infrastructure encompasses data centers around the world and scores of ML models, exacerbating the challenges of efficient debugging workflows.
In the last two years, a new internal toolkit we call HawkEye has propelled exponential improvements. HawkEye has become a powerful resource for monitoring, observability, and debuggability of the end-to-end ML workflow that powers Meta’s ML-based products.
We believe that the responsible advancement of AI is a shared commitment. So, in this article, we describe HawkEye’s design for the community. As we continue with the project, we expect to share what we have learned by solving the challenges of ML debugging at scale.
Streamlining Workflow, Supercharging Productivity
HawkEye is part of the Prediction Robustness program that Meta created to innovate tools and services to ensure the quality of our products that rely on ML model predictions. HawkEye includes infrastructure for continuously collecting data on serving and training models, data generation, and analysis components for mining root causes. It supports user experience (UX) workflows for guided exploration, investigation and initiation of mitigation actions.
With HawkEye, we have improved troubleshooting by significantly reducing the time spent on debugging complex production issues and simplifying operational workflows. Critically, it has enabled non-experts to triage complex issues with minimal coordination and assistance.

As a happy result, identifying and resolving issues in production workflows for features and models got simpler. It no longer requires specialized knowledge and familiarity with the processes and telemetry involved, and it minimizes substantial coordination across different organizations. HawkEye has lessened the pressure for on-call engineers to debug the models, and it has helped us share notebooks and code for root cause analyses on small parts of the debugging process.
HawkEye’s decision tree enables continuous collection of data on serving and training models, allowing users to navigate and identify the root cause of complex issues, streamlining the process.
To offer a hypothetical example: Formerly, the debugging scenario for a product team troubleshooting an anomaly on an AI-recommended Instagram feed might require assembling a range of expertise within Meta. It would include team members who manage the serving aspect of the model, those who built the serving model itself and other people who are responsible for working with the data behind the training process. All of these people would gather together to unearth the root causes of the issue in order to solve it. HawkEye essentially streamlines that very complex process in a single product.
HawkEye’s Essential Components
Machine learning plays an important role in many of Meta products and services. We use it for recommendations, understanding and generating content, and more. Putting ML models into production entails creating workflows that include the data pipelines of information needed for model training, others to build and improve models over time, evaluation systems for testing, and inference workflows to use the models in products.
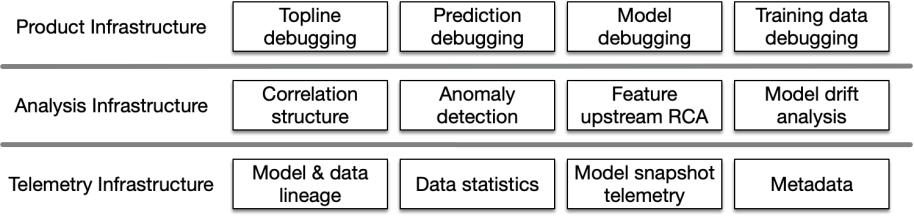
There are three main components needed to build a solution like HawkEye.
- The first is the collection of instrumentation data, which includes information about the model, the data, and the training process. This also includes the lineage of the data sets used in the training process.
- The second is analyzing this data. We analyze the large volume of data using algorithms to detect anomalies, correlations, and root causes. This analysis is done for both the data and the internal state of the trained model.
- The third component is the product layer, which presents all the information in a guided experience. ML model developers can navigate through different artifacts related to prediction time, training time, and the features used. HawkEye suggests an issue’s possible root cause based on the anomalies and correlations detected.
In addition to its decision tree, HawkEye includes real-time feature isolation, implementing model explainability and identifying a list of ranked features responsible for prediction anomalies. HawkEye isolates upstream causes of feature issues using a visual workflow to facilitate root-cause analysis, tracking the lineage of upstream data and pipelines. Diagnosing model snapshots, HawkEye compares current snapshots with operationally stable ones and identifies issues with weights, biases and potential improvements.
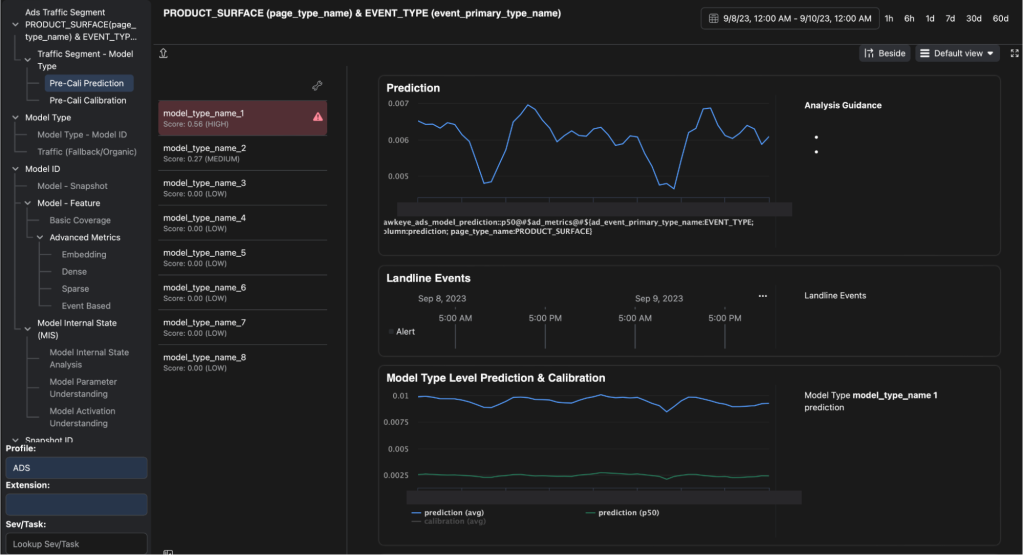
As we built HawkEye, our prioritization was driven by system reliability and hotspots within the ML workflow. As an end-to-end debugging solution, the most significant challenges we faced were integrating disparate and incomplete data lineage systems, datasets, and Root Cause Analysis (RCA) platforms, scaling it in near-real time, as well as achieving alignment and collaboration across multiple teams and organizations.
Reducing the traditional complexity of debugging at scale is important work for companies that rely on AI. We hope the community benefits from the insights we share here.